In this article, I am going to tell you How to Scrape Data Using Proxies. so if you want to know about it, then keep reading this article. Because I am going to give you complete information about it.
Data scraping using proxies refers to the practice of using proxy servers to collect data from websites or online sources while maintaining anonymity and avoiding IP blocking or rate limiting. Data scraping, also known as web scraping, involves extracting information from websites, such as text, images, prices, or any other structured data, for various purposes like research, analysis, or business intelligence.

Today’s article focuses on the same, i.e., “How to Scrape Data Using Proxies” The articles entail each bit of information necessary for you to know.
Let’s get started!✨
Table of Contents
How to Scrape Data Using Proxies?
You can assess the importance of data collection for different companies worldwide by a prediction that global data creation is expected to reach 180 zettabytes by 2025!
Data has become a valuable asset when it comes to professional analysis and better decision-making.
There is a traditional way to collect data though, it is a time-consuming and cumbersome task when you have to go through thousands of websites. Nowadays, web scraping is an efficient alternative to extracting data from websites.
You can save your time and resources by using proxies, bots, and web scrapers to do your job!
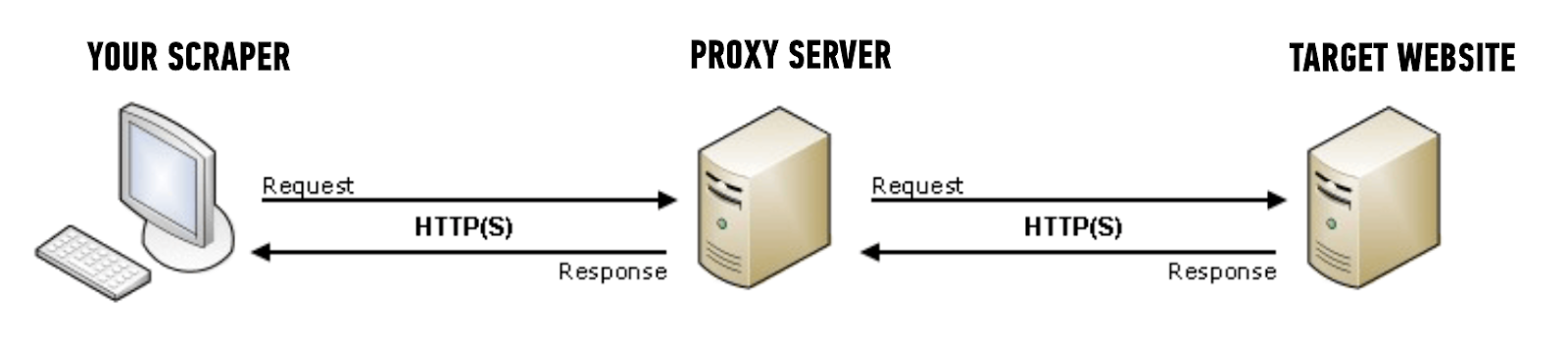
In basic terms, a proxy acts as an intermediary server that stands between your device and the target website.
Since web scraping requires a lot of requests made to a server from an IP address, the server may detect too many requests and block the IP address to stop further scraping. This is where web scraping proxy helps by distributing requests across multiple IP addresses, reducing the chance of detection and blocking.
A proxy can channel your requests through a different IP address, effectively masking your identity and IP location. So, work won’t be hindered, and you can continue scraping as the IP address is changed and won’t cause any issues. It also helps in hiding the machine’s IP address as it creates anonymity.
This ability to switch IP addresses is the basis of efficient data scraping, allowing you to access websites without revealing your true identity and avoiding IP-based restrictions.
Continue reading as we explore the art of web scraping using proxies, highlighting the strategies, best practices, and considerations that pave the way for successful data extraction!
What are the Types of Web Scraping Proxy?
Now that you know what a proxy is, let’s get to some of its widely used types. There are four basic types of proxies:
1. Data Center Proxy
These proxies come from cloud service providers and are occasionally flagged due to their immense usage by people. However, because they are less expensive, a set of proxies may be gathered for web scraping activities.
2. Residential IP Proxy
Because residential proxies use IP addresses from local ISPs, the websites cannot tell if the visitor is a scraper software or a genuine person. They are more expensive than Data Center Proxies and may result in legal consents because the owner is unaware you are utilizing their IP for site scraping activities.
3. Mobile IP Proxy
As the name suggests, mobile IP proxies use IP addresses from private mobile devices and show a great deal of resemblance with Residential IP Proxies. Because mobile network operators offer them, they are quite expensive. They may result in legal consent because the device owner is unaware if you are utilizing their GSM network for web scraping.
4. ISP Proxy
Static residential proxies are provided by servers in data centers and used for detecting real users. ISP proxies can be a mix of data center and residential proxy servers.
What are the Basic Steps to Start Data Scraping Using Proxies?
Data scraping tools and proxies have made the process of data extraction relatively easier and speedier. Here are some basic steps to follow to enjoy data scraping:
1. Choosing the Right Proxy Type
Selecting the appropriate proxy type is the first step to consider before you begin data scraping.
There are two main categories of proxies: residential proxies and data center proxies. Residential proxies utilize genuine IP addresses from internet service providers, offering a higher level of anonymity and authenticity. On the other hand, data center proxies originate from data centers, offering faster speeds and scalability.
The choice between the two depends on your specific scraping needs, budget, and desired level of anonymity.
2. Defining Your Scraping Objectives
Clarity in your scraping objectives is vital. Are you scraping data for market research, competitor analysis, SEO monitoring, or something else?
Defining your goals guides your approach, helping you identify the websites to target, the data points to extract, and the scale of your scraping operation.
Take time to ask yourself the basic questions to have a smooth data scraping experience!
3. Tools and Libraries
Using the right tools and libraries can effectively smooth the data scraping process.
Popular libraries like Beautiful Soup, Scrapy, and Selenium offer powerful functionalities to navigate website structures, extract data, and automate interactions. These tools enable you to write scripts that mimic human browsing behavior, ensuring efficient data extraction.
Effective Strategies for Data Scraping Using Proxies
Now that you’re familiar with the basics and types, let’s explore the strategies that optimize your data-scraping efforts using proxies:
1. IP Rotation for Anonymity
One of the primary advantages of proxies is their ability to rotate IP addresses. IP rotation involves periodically changing the IP address you use for scraping. This dynamic approach mimics natural browsing behavior and prevents websites from detecting and blocking your scraping activities based on a single IP address.
2. Implementing Rate Limits
Responsible scraping involves respecting websites’ terms of use and rate limits. By controlling the frequency and volume of your requests, you avoid overloading servers and maintain a smooth interaction with the website. Proxies facilitate rate limits by allowing you to distribute requests across multiple IP addresses.
3. Handling Captchas and Cookies
Websites often deploy CAPTCHAs and cookies to distinguish between human users and bots. Proxies can help manage this challenge by enabling you to bypass CAPTCHAs and cookies or by rotating IP addresses to avoid triggering these security mechanisms.
4. Bypassing Geo-location Restrictions
Some websites restrict access to specific regions. Proxies allow you to choose an IP address from a desired location, effectively bypassing geolocation restrictions and enabling you to scrape region-specific data.
Moreover, geo-targeted content scraping is on the rise, more than half of the marketers are utilizing proxies to gather region-specific data for localized marketing campaigns and audience targeting.
5. Monitoring Proxy Health
The effectiveness of your scraping operation depends on the health of your proxies. Regularly monitor the performance, speed, and reliability of your proxies to ensure flawless data extraction. Proxy management tools can help you in this process by providing insights into proxy health.
Best Practices for Ethical Data Scraping
Ethical considerations are paramount in the data scraping process. You can follow these best practices not only to maintain your reputation but also to ensure your scraping activities are aligned with legal and ethical standards:
1. Respect Robots.txt
Many websites have a robots.txt file that outlines which parts of the website can or cannot be scraped. Following the directives in the robots.txt file showcases ethical scraping practices and prevents unnecessary conflicts.
2. Avoid Overloading Servers
Practicing responsible scraping involves avoiding aggressive and excessive requests that could overload servers. Implement rate limits, delays, and IP rotation to ensure your scraping activities don’t disrupt website operations.
3. Adhere to the Terms of Use
Review and respect the terms of use of the websites you intend to scrape. Some websites explicitly prohibit scraping activities. Complying with their terms not only maintains ethical standards but also prevents potential legal consequences.
4. Choose Reputable Proxy Providers
Select proxies from reputable providers, like Smart Proxy by Crawlbase, that offer high-quality, reliable services. Such reliable proxy providers ensure that the IP addresses you use are legitimate, reducing the risk of bans and improving the success rate of your scraping tasks.
Conclusion:)
Data scraping with proxies is a powerful tool providing many insights and information. According to research, about 26% of internet users are utilizing proxy servers for web surfing.
By selecting the right proxy type, defining your scraping objectives, using appropriate tools, and following ethical guidelines, you can navigate the web’s complexities and extract valuable data while respecting the boundaries set by websites.
The data scraping technique utilizing proxies empowers you and your company to take advantage of the power of information to make data-driven decisions.
Read also:)
- How to Redirect HTTP to HTTPS: A-to-Z Guide for Beginners!
- How to Open ZIP File in Mobile: A-to-Z Guide for Beginners!
- How to Build a Successful eCommerce Brand: A-to-Z Guide!
So hope you liked this article on How to Scrape Data Using Proxies. And if you still have any questions or suggestions related to this, then you can tell us in the comment box below. Thank you so much for reading this article.